
Right Flow, Conclusion

This is the conclusion to Right Flow, in which we began talking about the simple pattern that most projects exhibit. We gave some examples of non-tech projects that demonstrate this pattern. And we talked about how software engineering, for one, over-complicates the depiction and management of this pattern. Now, this is where the article has to get technical - but hopefully at the end some general non-tech insights will have been revealed.
{kind=link}
Git Flow
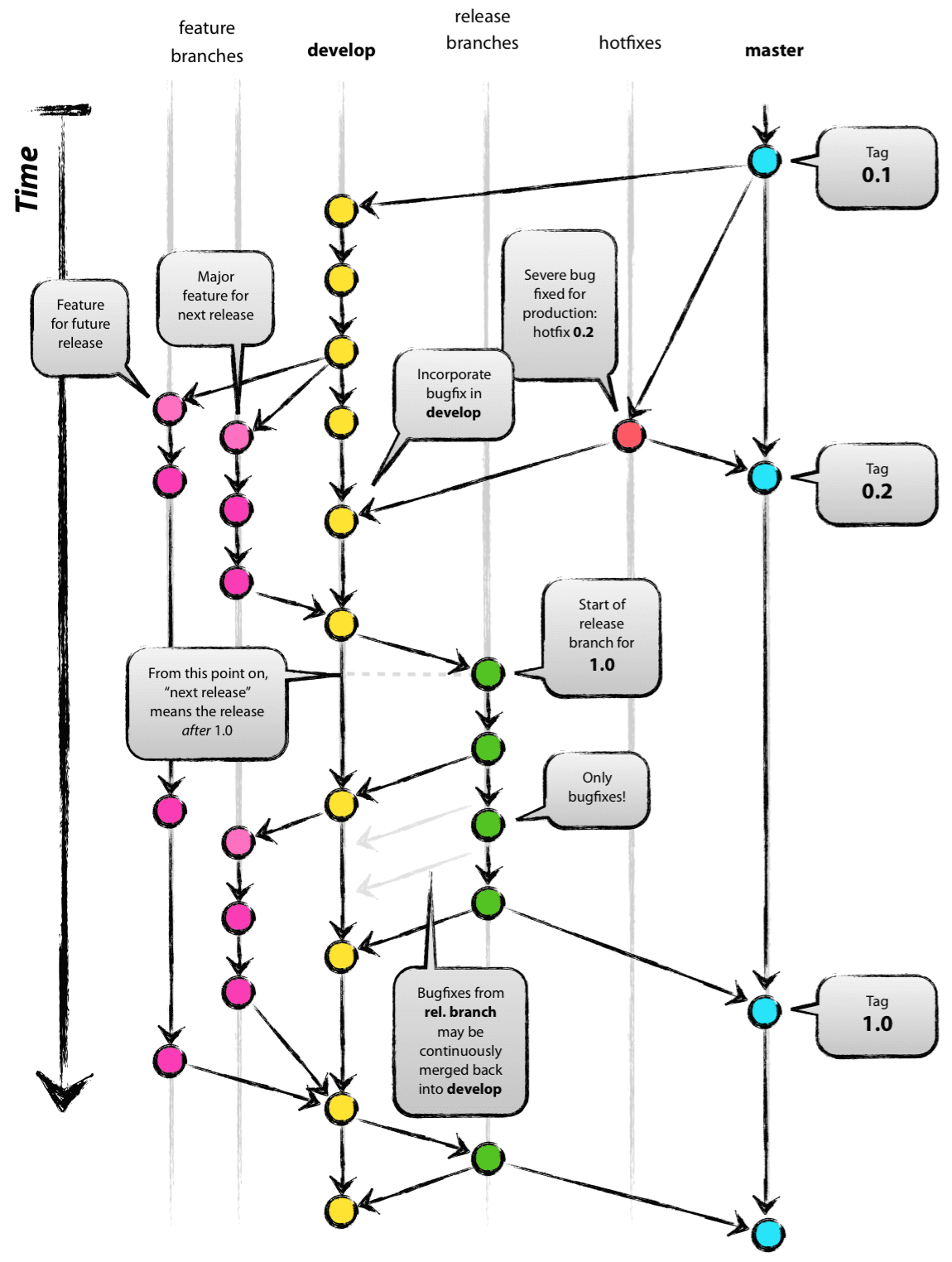
In the Git Flow model, there are two persistent branches of the repository: Master and Develop (lowercase in practice). The simplest summary of these two are: you release in Master, and you do work in Develop. But to support stepwise progression to targets (releases), and to support multiple developers across one or more teams, Git Flow includes Work Branches.
Work Branches are transient in the repository. They include Feature, Release, and Hotfix, and cover two categories of work: Developing a Release and Releasing a Release. The Feature Branches are used when developing a release, and either Release or Hotfix Branches are used for releasing a release. Commonly the Feature Branches are NOT distributed to all clones of the repository; they are kept local to a single developer while s/he works on the feature. This last point is a Huge Choice that directly impacts the frequency of integration (of features/changes).
There's so much one can say about the details of Git Flow...and if you know Git Flow now is a great time to recall those details from memory. I won't get into them, rather I am going to point out issues with Git Flow that kinda forced us all into over-complexity. And then I will show how Simple Flow alleviates all that mess.
Integrate Early
Feature Branches typically are created in a developer's local repository clone, and not shared with other repository clones. The developer works on the feature and then when ready, merges into the Develop Branch...finally sharing the work with other repository clones. Thus Feature Branches are intentionally designed to keep work local to the developer. The effects of this is that the work is not integrated early and the work is likely not run through the project's unit tests. In other words, Feature Branches encourage late integration of unreleasable code. I say unreleasable because code that has not passed the project's unit tests is, by definition, not releasable. This is an issue we all experience with Git Flow.
Amorphous Targets
If you browse the structure of a Git repository during the work towards a target (e.g., 2.1), you don't see the target anywhere. You see tags of previous targets, you see Develop and Master, and maybe if things aren't cleaned properly you see old Release and Hotfix Branches. Where's the target/s? If you look at the commit log you see features being merged in, but still no sign of target/s. Thus the Git Flow design intentionally leaves out the targets until the target has nearly been reached. This is another issue we all experience with Git Flow.
Simple Flow
Now picture everything you've got right now...I'm not proposing taking a single thing away. Add in a persistent branch for each target, ideally named TargetOne, TargetTwo, TargetThree, and so on as appropriate for your project. Add in that you merge every commit of your Feature Branch into its Target Branch and push. What do we have now? Something simple but profound...
- Continuous Integration builds of all feature work, as soon as work is committed.
- Targets are clearly defined in all repository clones.
- And here is a big one: automatic merging following the linear progression of targets.
So if I am Sam Developer working on Authentication Module feature for TargetOne, my work gets committed to my Feature Branch and then merged to its Target Branch. This work gets pushed to the origin repository clone, which triggers a continuous integration build (i.e., compile, unit tests). An automated job merges my commit/s from TargetOne to TargetTwo, TargetThree, etc. and Master. Result: everybody has everybody else's stuff as early as possible. No late surprises. And the system is always in a releasable state (assuming tests have not failed).
The release mechanics you are used to work just fine with Simple Flow. When targets in real life have been shifted, meaning when version 2.1 becomes Latest, 1.21 becomes Previous, and 3.0 becomes Beta, then you simply "move" the branches from right to left. TargetOne gets deleted (it's been tagged so no worries), TargetTwo becomes TargetOne, TargetThree becomes TargetTwo, and Master gets copied to a new TargetThree.
Conclusion
There are many advantages that stem from using persistent Target Branches, the biggest being that we are all integrating early and the system is always in a releasable state. Part of that is that developers never go off the grid...their work is always shared and tested and reviewed. I came up with Simple Flow several years ago and with a large team of developers, we never found it lacking. To the contrary, it saved our butts many times.
I hope you give Simple Flow a try. Make your Targets the focal point of Your Flow.